Nodes/Document 是 LlamaIndex 中最核心的概念,用來封裝任何數據源的通用容器,例如PDF、Word、API或資料庫數據。其中包含了元數據(Metadata)、關係(relationships)兩大屬性。Node 通常代表 Document 的一個「片段(Chunk)」,為文本片段、圖像或其它類型。
這邊的概念是筆者認為 LlamaIndex 中最重要的地方,因為它串起了整個 RAG 系統「文字溝通的精隨」,必須先理解 Documents 的原理才能懂之後各階段的內容,一開始會建議大家先讀取一份檔案後對每個欄位自己修改看看,去體會欄位之間的差異。以下將介紹各欄位使用方式:
(可以想像成不要給 GPT 看的欄位內容,如路徑、作者等,對於回答問題沒有幫助的資訊。)
(跟User問題無關的欄位可以過濾掉,如檔案路徑等,給開發人員看的資訊。)
(建議使用預設就好,除非有特殊需求。)
from llama_index.core import Document
from llama_index.core.schema import MetadataMode
document = Document(
text="This is a super-customized document",
metadata={
"file_name": "super_secret_document.txt",
"category": "finance",
"author": "LlamaIndex",
},
excluded_llm_metadata_keys=["file_name"],
excluded_embed_metadata_keys=["category", "author"],
metadata_seperator="::",
metadata_template="{key}=>{value}",
text_template="Metadata: {metadata_str}\n-----\nContent: {content}",
)
# 用於檢視 Documents 發送給 LLM 時的文字內容
print(
"The LLM sees this: \n",
document.get_content(metadata_mode=MetadataMode.LLM),
)
# 用於檢視 Documents 執行 Embedding 時的文字內容
print(
"The Embedding model sees this: \n",
document.get_content(metadata_mode=MetadataMode.EMBED),
)
pip install llama-index
(Metadata支援自定義內容,可自行增減。)
from llama_index.core import SimpleDirectoryReader
path = ".\iThome鐵人賽活動簡章-20240614.pdf"
reader = SimpleDirectoryReader(input_files=[path])
documents = reader.load_data()
# 查看結果
print(f"總共分為{len(documents)}個document")
print(f"Document內容:{documents[0].text}")
print(f"Document Metadata:{documents[0].metadata}")
# ------分隔線------
# 查看結果
In[1]: print(f"總共分為{len(documents)}個document")
Out[1]: 總共分為3個document
In[2]: documents[0].text
Out[2]: '2024 iThome 鐵人賽 活動簡章 \n1 \n 壹、 活動宗旨 \n鼓勵 IT 人分享技術心得 、促進學習與交流,振興 繁體中文 IT 文章創作 。 \n貳、 主辦單位 \n電週文化事業 股份有限公司 (iThome) \n參、 賽制與獎項 \n分為「主題競賽」 、「自我挑戰」 以及「佛心分享」三大 挑戰方式 ,參賽者根據 下表說明依 所選參賽主題、\n切題發文,於限定賽期內堅持 30天不中斷, 即可完賽。 獎勵辦法如下: \n賽 組 主題競賽 佛心分享 自我挑戰 \n參賽主題 根據官網公布主題擇一參賽 ,例如: \nAI & Data 、DevOps、GenAI、IT管理、\nModern Web 、Mobile Development 、\nSecurity、Software Development 、影片\n教學等。 從官網公告 佛心分享主題\n擇一參賽,例如:\nSideProject30 、IT人自學\n之術、我的私藏工具箱、\nIT人的工作軟技能等 如無法在主題競賽中找\n到適合的參賽主題,可\n在「自我挑戰 」賽組自\n訂主題參賽,但自訂主\n題仍應與 IT 相關。 \n完賽證明 無論賽組,只要完成 30天連續挑戰,都頒發 完賽證明乙紙 \n評選獎項 主題競賽完賽作品,經評審委員會評選後、\n擇優獎勵;獎項由評審會議視參賽者及作品\n水準議定,必要時得以從缺。 \n \n冠軍(每主題 1名) \n1萬元獎金、獎盃乙座 ,以及賽季紀念品 \n各主題完賽人數達 100人,每逾 50人,額\n外增設 1個名額。 \n \n優選(每主題 2名) \n獎盃乙座 以及賽季紀念品 \n各主題完賽人數達 100人,每逾 50人,額\n外增設 2個名額。 \n \n佳作(若干名) \n獎牌乙面 以及賽季紀念品 \n不分主題,由評審委員會 依賽事整體 作品\n水準,議定標準、擇優入選 ,名額不限。 \n 不列入計分評選。 \n \n不頒發冠軍、優選與佳作\n獎項。 \n \n評審委員會將依賽事整體\n作品水準與作品實用性議\n定標準、 擇優列出推薦文\n章列表,並於得獎公告\n之。 \n \n名列推薦文章之作者將額\n外獲得賽季紀念品。 不列入計分評選。 \n \n不頒發冠軍、優選與佳\n作獎項。 \n \n \niThome 鐵人賽鼓勵選手組團、互相打氣勉勵,因此額外推出「 組隊挑戰」及相應獎勵 :無論「主題競\n賽」、「自我挑戰」或是「佛心分享」之參賽者,均可透過賽事網站機制組成團隊進行「 組隊挑戰」。團\n隊應至少有 3名成員(上限不拘),且須約定於同一日開賽 (組隊挑戰最早 08/01組隊報名,並於 08/02開\n賽,最晚於 09/14組隊報名並於 09/15開賽);當團隊成員皆完賽 ,除仍將獲得 個人原有 完賽證明外,還\n將額外獲得團隊鍊成獎牌(每人乙面) 。主辦單位也將針對完成團隊挑戰之團隊,額外頒發以下兩個獎項: \n⚫ 最佳團隊獎( 1隊):共享 團隊布幟乙面與獎金 5千元整 \n平均成績最高團隊獲獎( 因需計分評選,因此團 隊成員均需為 「主題競賽 」參賽者)。 \n⚫ 眾志成城獎( 1隊):共享團隊布 幟乙面 \n完賽人數最多之團隊獲獎。 \n \n '
# 查看元數據內容
In[3]: documents[0].metadata
Out[3]:
{'page_label': '1',
'file_name': 'iThome鐵人賽活動簡章-20240614.pdf',
'file_path': 'iThome鐵人賽活動簡章-20240614.pdf',
'file_type': 'application/pdf',
'file_size': 380946,
'creation_date': '2024-09-11',
'last_modified_date': '2024-09-11'}
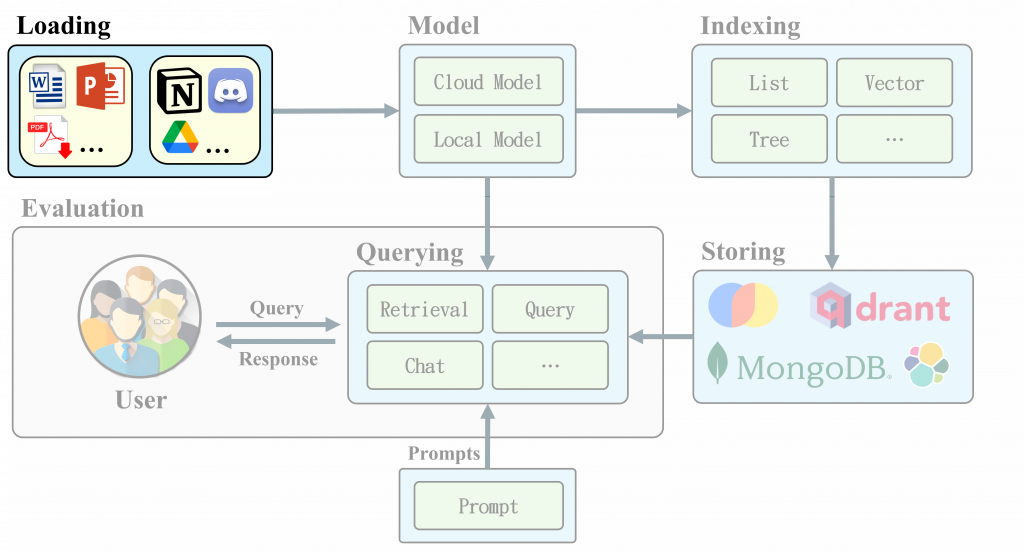
我們現在有了 Documents ,但因為受限於Embedding、LLM 輸入大小的限制,無法一次將完整內容輸入模型中訓練或生成,所以我們需要把 Document 的內容切割成更小的「Chunk」,也就是 Nodes 。也可以透過 Node Parser 解析各種格式資料,如Json、HTML、Markdown等。
(圖片來源:自製投影片)
接著我們來瞧瞧 Nodes 是什麼?接續上述程式,將以下程式輸入並執行。
from llama_index.core.node_parser import SentenceSplitter
# 讀取 Documents(上方的程式碼部分)
...
# 建立 Node Parser。 參數設定 SentenceSplitter(chunk_size=1024, chunk_overlap=20)
parser = SentenceSplitter()
nodes = parser.get_nodes_from_documents(documents)
# 檢查結果
print(f"總共分為{len(nodes)}個Nodes")
print(nodes[0].text)
結果從3個 Document 變成 7 個Nodes,因為每一頁的內容超過預設大小,會將內容切分成多個 Nodes。詳細設定可以至官網查看[Node Parser](https://docs.llamaindex.ai/en/stable/module_guides/loading/node_parsers/modules/)。
# 查看結果
In [5]: print(f"總共分為{len(nodes)}個Nodes")
Out[5]: 總共分為7個Nodes
In [6]: nodes[0].text
Out[7]: '2024 iThome 鐵人賽 活動簡章 \n1 \n 壹、 活動宗旨 \n鼓勵 IT 人分享技術心得 、促進學習與交流,振興 繁體中文 IT 文章創作 。 \n貳、 主辦單位 \n電週文化事業 股份有限公司 (iThome) \n參、 賽制與獎項 \n分為「主題競賽」 、「自我挑戰」 以及「佛心分享」三大 挑戰方式 ,參賽者根據 下表說明依 所選參賽主題、\n切題發文,於限定賽期內堅持 30天不中斷, 即可完賽。 獎勵辦法如下: \n賽 組 主題競賽 佛心分享 自我挑戰 \n參賽主題 根據官網公布主題擇一參賽 ,例如: \nAI & Data 、DevOps、GenAI、IT管理、\nModern Web 、Mobile Development 、\nSecurity、Software Development 、影片\n教學等。 從官網公告 佛心分享主題\n擇一參賽,例如:\nSideProject30 、IT人自學\n之術、我的私藏工具箱、\nIT人的工作軟技能等 如無法在主題競賽中找\n到適合的參賽主題,可\n在「自我挑戰 」賽組自\n訂主題參賽,但自訂主\n題仍應與 IT 相關。 \n完賽證明 無論賽組,只要完成 30天連續挑戰,都頒發 完賽證明乙紙 \n評選獎項 主題競賽完賽作品,經評審委員會評選後、\n擇優獎勵;獎項由評審會議視參賽者及作品\n水準議定,必要時得以從缺。 \n \n冠軍(每主題 1名) \n1萬元獎金、獎盃乙座 ,以及賽季紀念品 \n各主題完賽人數達 100人,每逾 50人,額\n外增設 1個名額。 \n \n優選(每主題 2名) \n獎盃乙座 以及賽季紀念品 \n各主題完賽人數達 100人,每逾 50人,額\n外增設 2個名額。 \n \n佳作(若干名) \n獎牌乙面 以及賽季紀念品 \n不分主題,由評審委員會 依賽事整體 作品\n水準,議定標準、擇優入選 ,名額不限。 \n 不列入計分評選。 \n \n不頒發冠軍、優選與佳作\n獎項。'
Llama Hub 是一個數據讀取庫,使用者可以透過 Llama Hub 獲取各種數據接口。幫助從不同的數據源(如 DataBase、API 等)中提取數據,例如 DatabaseReader 可以用來查詢 SQL 數據庫,並將結果轉換為 Document Object ,大大減少了開發人員的負擔。
RAG 系統畢竟是基於語言模型而發展,因此「語言的內容/格式」就顯得格外重要,必須理解每次傳入模型的內容,才能在未來精進系統架構時更快速。當每個模型都使用多次後,會慢慢發現各個模型對於格式、文字長度的偏好,如太長可能會有幻覺、表格資料使用 Markdown/Json 表達會更加精確等。 LlamaIndex 提供了多種讀取的方式與接口,大大的減少了開發人員的困擾,只需要在 Llama Hub 上搜尋相關的程式碼就能快速整合。接著我們將會介紹 LlamaParse ,如何將文字轉換成 LLM 喜歡的風格~

